So it started when I wanted my car to identify the Amsterdam scanning cars (cars that drive around and scan your license plate for various reasons), I took it as a learning experience to improve my AI and Python skills.
I’ve already read some books about vision AI and set up Marvin the training station.
Now the time came to choose the right starting dataset, base model, and algorithms, then get some extra sample pictures for the Scanning cars and push it to Marvin to crunch his crunch.
From comparisons I’ve read on the net I knew I wanted to use MXnet framework to train on GPU efficiently, and I wanted VGG as the starting model for fine tuning.
MXnet was a hassle to set up, luckily Dr. Adrian Rosebrock from Pyimagesearch came to the rescue in one of his courses (DL4CV book 3 chapter 12). He outlined a similar case study, and he added a good dataset to boot namely the Stanford Cars Dataset.
The Stanford Cars Dataset comprises of 16k jpg pictures of different cars with labels around them stating the model of the car.
It’s a relatively small dataset, but it fit my needs perfectly since I wasn’t planning to start with many photos of scanning cars, so if I added a small amount of pictures in my Scaning-car category they will drown in comparison to the amount of photos in the other categories (leading to possible overfitting).
I will add here the DL link to the starting dataset later
For the the neural network I went with VGG16 3x3 pretrained on the mighty ImageNet (I will post this exercise in another Topic),
It’s slow, but since it’s a small dataset that I’m adding to the model (aka fine tuning) the sluggishness isn’t an issue, on the plus side the accuracy of VGG is worth the wait.
After I finish this task I’ll try to do this on Tensorflow with SSD, but that’s for V=2.
For the learning algorithm I used MXnet implementation of SGD which makes it fast.
Rosebrock and wikipedia explained the concept of gradient decent better than I could, so here:
Or if you wanna the python:
The Pyimagesearch DL4CV book series has a great step by step explanation of SGD, much clearer (to me) than the wikipedia page.
Next I collected and labeled a bunch of Scanning cars I saw on the street and on the Internet.
I had to modify the Stanford dataset to add my category (Scanning-car) next to all the other car companies such as BMW or Volvo, and add my newly added jpg information to the csv files.
Next, when all was in place, the stars were aligned and the video cards fired up we started crunching. I will upload a separate post in this thread detailing the learning process, the fine tuning and the graphing of the results.
After trainging the model for about 90 EPOCHS and establishing the best parameters for the training, it was time to use my newly created model with an inference code and some random photos to check how reliable it is:
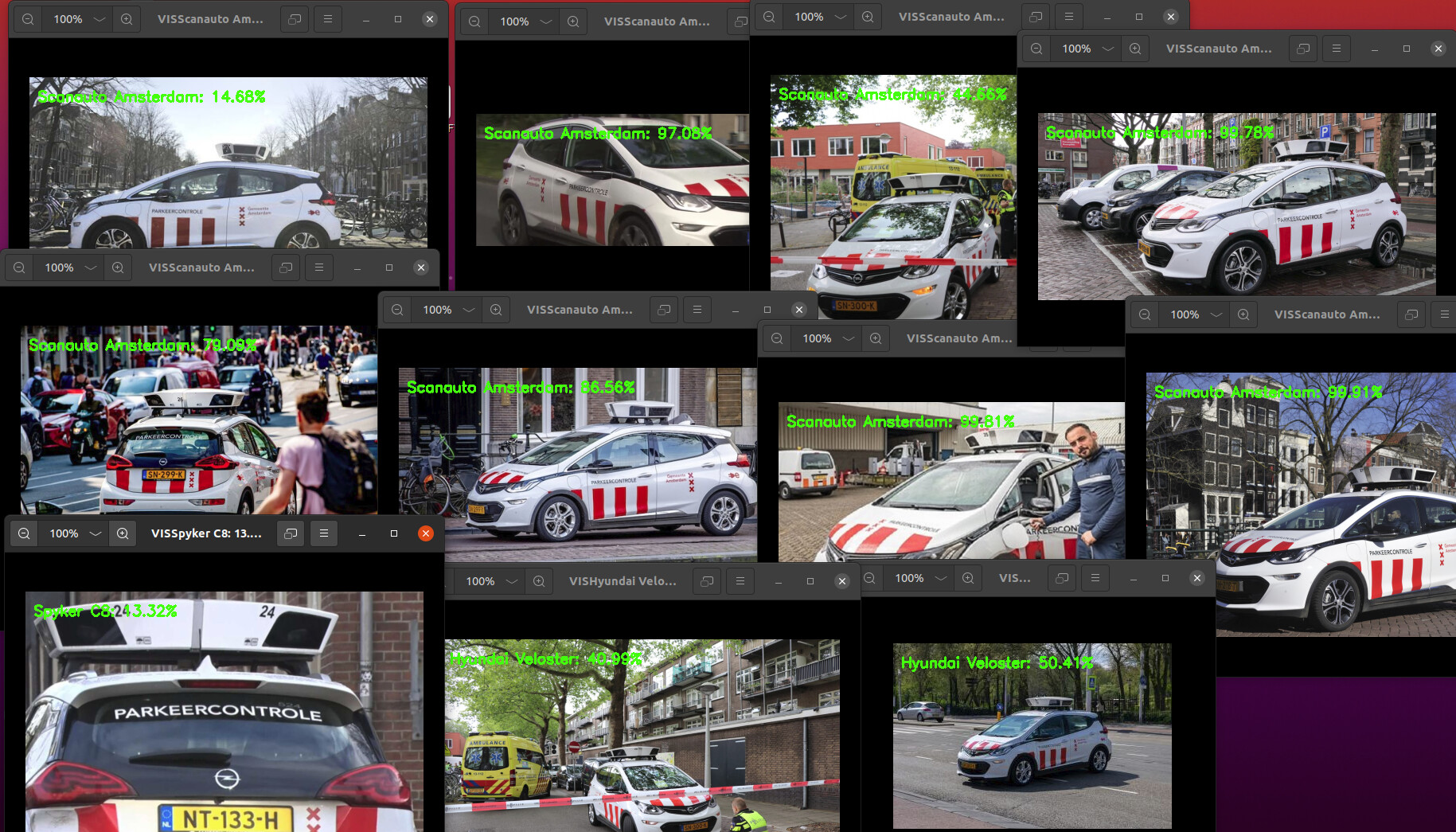
V=1 succeeded beautifully when Marvin detected 8 from 11 images correctly.
Code and dateset available here:
The beautiful code is mostly taken from Adrian’s work, the annotations are great, and he elaborates on each part in his books, config folder holds basic info.
python build_dataset.py
~/mxnet/bin/im2rec ~/cars-2/lists/train.lst “” ~/cars-2/rec/train.rec resize=256 encoding=’.jpg’ quality=100 && ~/mxnet/bin/im2rec ~/cars-2/lists/test.lst “” ~/cars-2/rec/test.rec resize=256 encoding=’.jpg’ quality=100 && ~/mxnet/bin/im2rec ~/cars-2/lists/val.lst “” ~/cars-2/rec/val.rec resize=256 encoding=’.jpg’ quality=100
python fine_tune_cars.py --vgg vgg16/vgg16 --checkpoints checkpoints --prefix vggnet --start-epoch 19
python vis_classification-2.py --checkpoints checkpoints --prefix vggnet --epoch 33
V=1.2 increase dataset, more scanning-car pictures. Add pictures and videos from friends.
V=2 succeed in doing this training on TFOD with SSD